In earlier posts about Google’s and Twitter’s onboarding tips we mentioned they would absolutely be measuring the impact of Tips and Tours to get the maximum uplift of user understanding and engagement.
One method is just by simply looking at your analytics and checking the click-thru rate or whatever other CTA (call-to-action) outcome you desired. But 2 big questions loom:
- Is what I’m doing going to be a better experience for users?
- How do you “continuously improve?
In recent years – rather than a “spray and pray” approach, it’s favorable to test-and-learn on a subset of your users. Facebook famously run many experiments per day and because their audience size and demographic diversity is massive they can “continuously improve” to killer engagement. If they “burn a few people” along the way its marginal collateral damage in the execution of their bigger goals.
That sounds mercenary but the “greater-good” is that by learning effectiveness of your experiments will result in better user experiences across the entire user-base and more retained users.
What do I mean by Mobile Onboarding?
Onboarding is the early phases of a user’s experience with your App. A wise Product Manager recently said to me “on-boarding doesn’t make a product… …but it can break the product”.
If you are familiar with Dave McClure’s “startup metrics for pirates” – then the goal of Onboarding is to get the user to the “AR” in “AARRR”. To recap:
- A – Acquisition
- A – Activation
- R – Retention
- R – Referral
- R – Revenue
So Onboarding’s “job” is to get a user Activated and Retended or Retentioned (can I make those words up? OK, OK “Retained”).
Because a user’s attention-span is slightly worse than a goldfish your best shot is to get the user Activated in the 1st visit. Once they are gone, they may forget you and move onto other tasks.
Yes – but specifically what do you mean by Onboarding?
Activation is learning how a user gets to the “ah-ha” moment and cognizes your Apps utility into their “problem solving” model. Specific actions on onboarding are:
- Get them some instant gratification
- Get them some more instant gratification
- Trade some gratification for a favour in return
- User registration
- Invite a friend
- Push notification permission
- Most importantly it is the education and execution of a task in the App that gets the “ah-ha” moment. This is often:
- Carousels
- Tips
- Tours
- Coachmarks
- A guided set of tasks
Progressive (or Feature) Onboarding
Any App typically has more than one feature. Many retailers, banks, insurers, real-estate, telcos (and others) have Apps that have multiple nuggets of utility built into the App.
This is because they have a deep, varied relationship with their customers and multiple features all need to be onboarded. We can’t decide what to call this yet – its “feature” driven – but the goal is to progressively deepen a user’s understanding and extracted value from the App.
So onboarding (and A/B testing) applies to more than the first “activation” stage of the App.
What is A/B testing?
A/B testing, or split testing, are simple experiments to determine which option, A or B, produces a better outcome. It observes the effect of changing a single element, such as the presenting a Tip or Tour to educate a user.
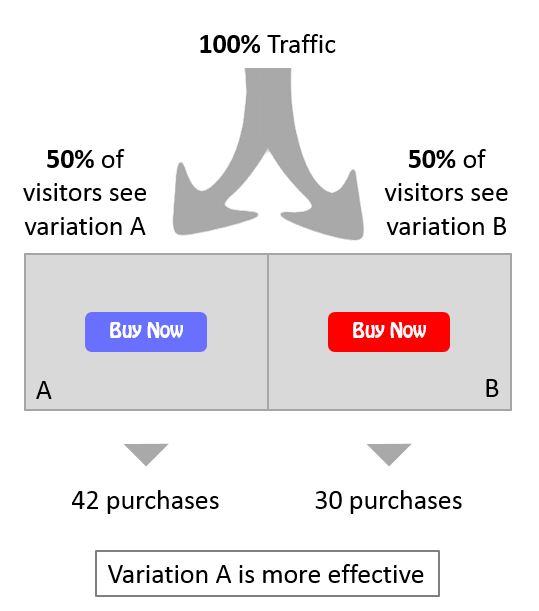
Champion vs Challenger
When the process of experimentation is ongoing, the process is known as champion/challenger. The current champion is tested against new challengers to continuously improve the outcome. This is how Contextual allows you to run experiments on an ongoing basis so you can continue to improve your Activation.
A/B Testing Process
Step 1: Form a hypothesis around a question you would like to test. The “split” above might be testing an experiment (based on a hypothesis) that running a Tip or Tour will influence a “Success Metric” of “Purchases”.
The “Success Metric” does not need to be something so obvious, it may be testing the effectiveness of an experiment to alter “times opened in last 7 days” across the sample population.
Here’s another example teaching a user how to update their profile and add a selfie.
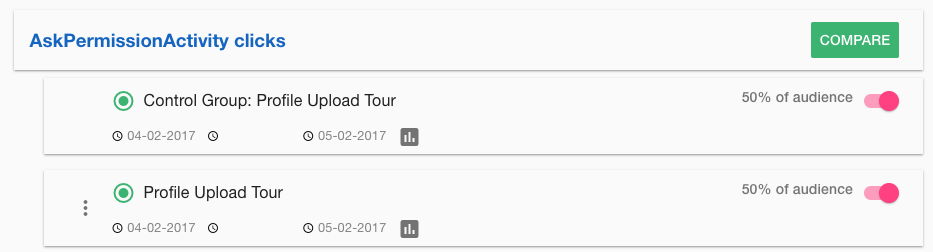
Step 2: Know you need statistical significance (or confidence). See the section below on this – it’s a bit statistical but in summary the certainty you want that the outcome of your experiment reflects the truth. Do not simply compare absolute numbers unless the two numbers are so different that you can be sure just by looking at them, such as a difference in conversion rate between 20% and 35%.
Step 3: Collect enough data to test your hypothesis. With more subtle variations under experiment, more data needs to be collected to make an unambiguous distinction of statistical confidence decided in Step 2.
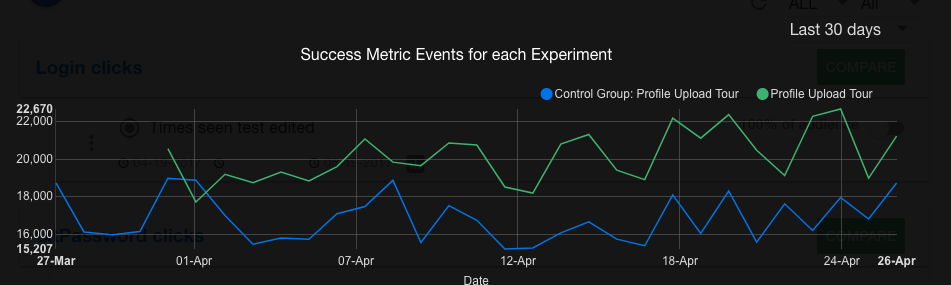
Step 4: Analyse the data to draw conclusions. Contextual provides you with the comparison of performance for every campaign grouped by the same “success metric”. The chart below shows the:
- Blue is the Control Group (Champion)
- Green is your Experiment (Challenger)
- The last 30 days history.
“Contextual automatically captures screen visits and button clicks without you needing to a-priori think about it”
Iterate
Step 5: Build from the conclusions to continue further experiment iterations.
Sometimes this might mean:
- Declaring a new “Champion”
- Refining a new “Challenger”
- Or scrapping the hypothesis.
The most impressive results come from having a culture of ongoing experiments. It will take some time but ultimately the Product Manager can recruit others in their team (developers, QA, growth hackers) to propose other experiments.
Statistical Significance
Picking the right metric
Running experiments are only useful if:
- You selected the correct “Success Metric” to examine. In Contextual we allow you to automatically chart your “Success Metrics” comparisons, but we also allow you to “what-if” other metrics. Contextual:
- automatically captures screen visits and button clicks without you needing to a-priori think about it.
- allows you to sync data from your backend systems so you can measure other out-of-band data like purchases or loyalty points etc.
A/A/B or A/A/B/B Testing
It has become more common to also duplicate identical running of an experiment to eliminate any question of statistical biasing using the A/B tool. If there is a variation between A–A or B/B is “statistically significant” then the experiment is invalidated and reject the experiment.
Sample Size and Significance
If you toss a coin 2 times its a lousy experiment. There is an awesome Derren Brown “10 heads in a row” show. Here’s the spoiler video! If you remember back to your statistics classes at College/University the “standard error” (not “standard deviation”) of both A and B need to NOT overlap in order to have significance.
Where T = test group count and C = converts count and 95% range is 1.96, Standard Error is:
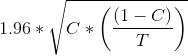
I’ll do a whole separate post on it for the geeks but using a calculator in the product is good enough for mortals 🙂
UPDATE: The geek post is here!
A/B testing vs multivariate testing
A/A/B is a form of multivariate testing. But multivariate testing is a usually a more complicated form of experimentation that tests changes to several elements of a single page or action at the same time. One example would be testing changes to the colour scheme, picture used and the title font of a landing page.
The main advantage is being able to see how changes in different elements interact with each other. It is easier to determine the most effective combination of elements using multivariate testing. This whole picture view also allows smaller elements to be tested than A/B testing, since these are more likely to be affected by other components.
However, since testing multiple variables at once splits up the traffic stream, only sites with substantial amounts of daily traffic are able to conduct meaningful multivariate testing within a reasonable time frame. Each combination of variables must be separated out. For example, if you are testing changes to the colour, font and shape of a call to action button at the same time, each with two options, this results in 8 combinations (2 x 2 x 2) that must be tested at the same time.
Generally, A/B testing is a better option because of its simplicity in design, implementation and analysis
Summary
Experiments can be “spray-and-pray” or they can be run with a discipline that provides statistical certaintly. I’m not saying its an essential step and the ONLY metric you want to apply to your App engagement – but as tools become available to make this testing possible you have the foundations to make it part of you culture.



