Smartphone manufacturers are clearly the earliest proponents of sophisticated digital product adoption techniques like mobile user onboarding flows and product walkthroughs but how are they faring in their global battle for hearts and minds?
A report by Electronics Hub in 2021 showed that out of 142 countries, 74 prefer Android over Apple 65 with Belarus, Fiji and Peru showing a draw. The survey methodology described in the report was based on sentiment analysis of over 347,000 tweets.
What was remarkable about the survey is that North America overwhelmingly prefers Android (yep you read that right) over Apple with Android averaging 32, over Apple 19 in terms of positive sentiment. Curiously Poland emerged as the world’s number 1 Android hater with 34% of tweets averaging negative. Latvia ranked as the world’s number one Apple hater with 35% tweets about Apple averaging negative.
Whatever religious standing consumers hold over either platform the sentiment doesn’t stack up when it comes to B2B and B2B2C mobile apps. A tally of Apple and Android SDKs for three of the most popular analytics firms Segment, Amplitude and Mixpanel tell a very different story. A sample of Business and Finance apps using SDKs for the aforementioned analytics firms reveal Apple as the clear front runner with almost double the number of SDKs over Android.
Love or hate when it comes to the question of how users feel the apps they use, analytics will provide some insight however they don’t provide any tools enabling quick response to change or influence user behaviour. App developers are largely limited to hard coding which extends to any user engagement strategies like mobile app user onboarding tours, product walkthroughs, contextual mobile tooltips, in-app FAQ’s and user surveys. Darryl Goede, CEO and founder of Sparkbox knows first hand how long and painful software development can be, however being able to use a low-code user engagement platform like Contextual allows his team to quickly respond to changes in user behaviour and maintain the love of Spark Pico users
React Native shares the love!. At Contextual we are noticing emerging B2B apps are trending towards Android particularly in Asia and South America however what we are also seeing is a preference for React Native for the development of both Android and IOS business apps. This is great news for Product Teams looking to accelerate their apps across both iOS and Android platforms. The good news is Contextual provides a simple easy to implement solution for creating and targeting mobile and web application user onboarding guides and walkthroughs and in-app contextual tooltips, FAQs and user surveys across each operating system.
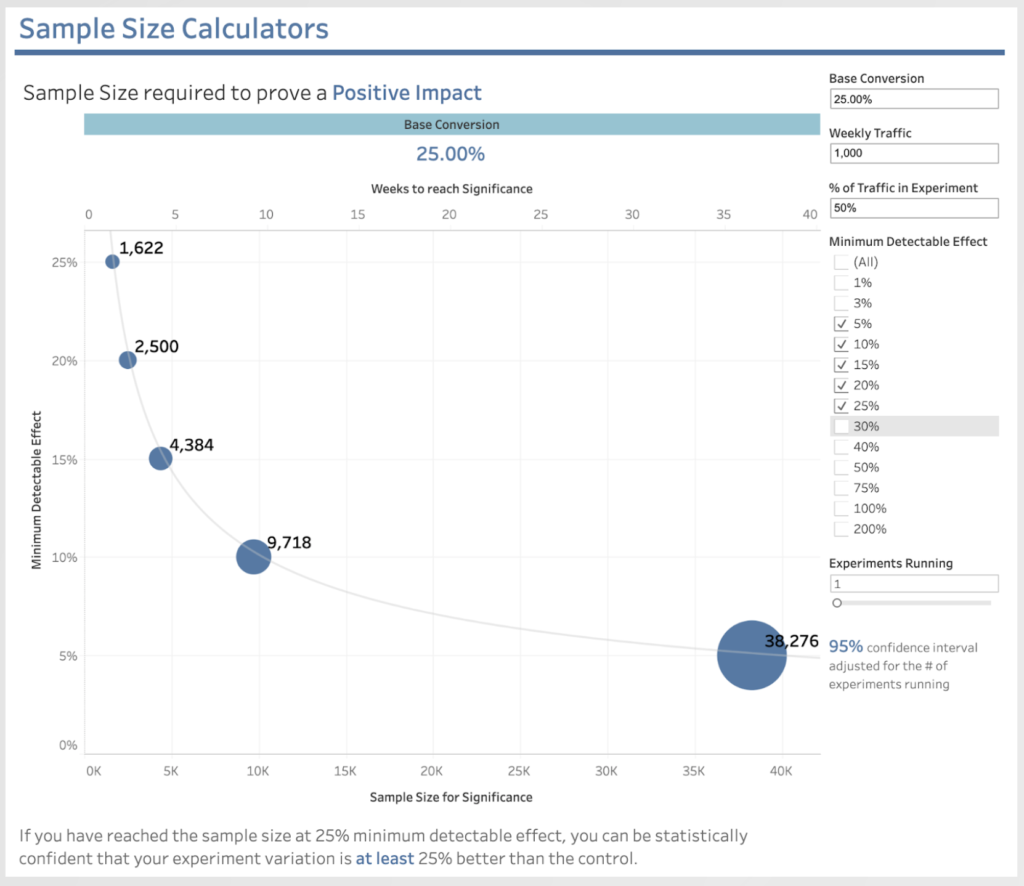
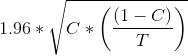 = 1.96 * SQRT(0.1 * (1-0.1) / 1000)= 0.00949
= 1.96 * SQRT(0.1 * (1-0.1) / 1000)= 0.00949