An essential component for a well-oiled machine that is a product-led company is feedback. It’s a tool that can help better your product, build meaningful connections with your users, and help you run a successful business.
But do you need a large quantity of feedback to translate it into valuable product improvements? Is any feedback a good enough lead to make changes? Does context matter?
This article will give some answers regarding realistic response rates, justifying changes based on feedback, and much more. So, let’s dive in!
Realistic Response Rates in Context
The concept of a response rate indicates the percentage of the users who offer feedback for your product, a feature of it, or the business in general. However, as we already know, feedback is contextual.
According to Survey Any Place, the average feedback response rate is 33%. The infographic shows the impact different mediums have on giving feedback. In contrast with the average rate throughout all feedback channels, a good NPS response rate is anything above 20%.
This goes to show that you should take into consideration the chosen feedback method when looking at response rates. It might be good practice to combine different ways of asking for feedback for optimal results.
Another thing you shouldn’t forget is that apps inevitably reach different types of people. This means that you can target your audience with different methods of feedback collecting as well. Diversify your feedback mediums for:
- Web and Mobile users
- Different user segments or user roles
- Different stages of a user journey
Try different methods for these and see what brings the best results – based on your OKR and JTBD of course! 🙂
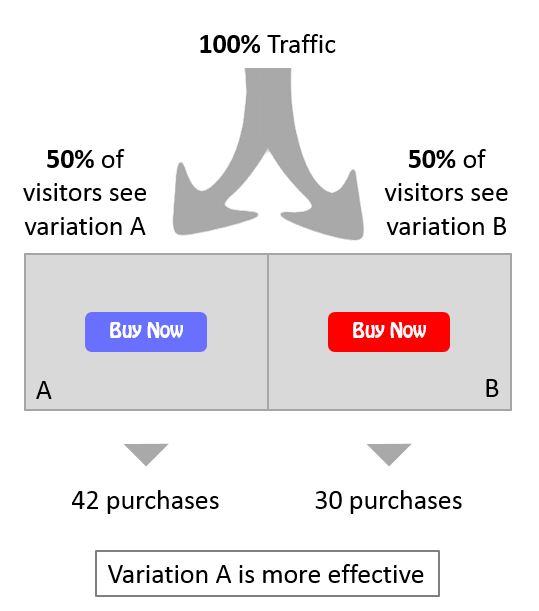
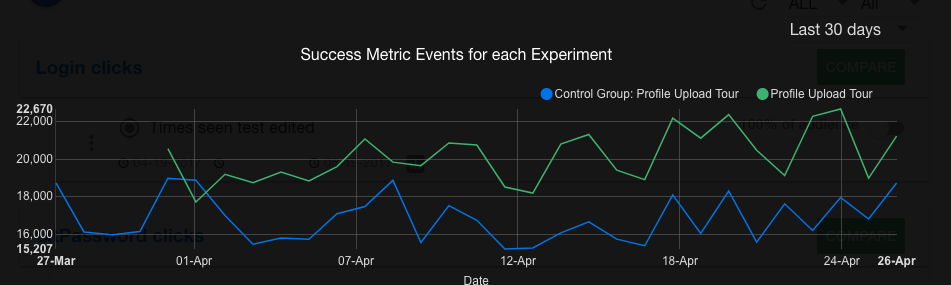
If you have a large sample of feedback (see these articles on statistical significance) consider A/B testing to determine what medium (mobile or web) of feedback are your users most comfortable with. This means that you give half of the target audience of users one form of feedback, while the other half are offered a different channel to express their opinion on your product. See which method is more successful in attracting your clients’ opinions and go from there.
There is no “one size fits all” when it comes to feedback. Figure out slowly what works for you and your users best!
Justifying Change Based on Feedback
As part of a product-led company, you probably already know that every piece of feedback is valuable. User feedback fills the gap between your expectations and the user experience. So, reviews are a testament to your efforts and also a great opportunity to improve your product where it is necessary.
With that being said, when does feedback justify change?
Surely, one negative comment or response is not something you, as part of a product-led company, should be discouraged by. However, in the next user journey mapping session, you can take a look at the user’s point of view and the reason behind their negative review. While a single piece of negative feedback is not a strong enough reason to implement significant changes, analyzing it might be a good idea for future developments of your product.
Statistically, change can be justified with just a 20% feedback rate. As response rates are, on average, around 33%, it’s safe to assume that most users who are willing to offer feedback for your app, fall into that 20%.
With their help, you can identify product improvement areas and plan your next user journey mapping according to the feedback you are getting. If you are able to incorporate feedback and change, your business is in the ideal market-fit bracket.
Not Receiving Enough Feedback
Positive feedback is desired, negative feedback can be a good lesson. But what if there is little to no feedback? If you’re a small startup with under 1000 users, you might find it difficult to get the reviews you need to justify changes or even keep your company running.
In this case, you should especially focus on implementing in-app feedback methods to ensure that you’re reaching your active and engaged users. Their feedback is the most valuable one when you’re working on a smaller scale. Of course, don’t forget about timing, as it is a significant component of feedback. Give your users enough time to experience your app before asking for their opinion.
Implementing changes with little feedback to back you up can be a risky business, but it can also drive users to give an assessment. It would be wise to start small when it comes to changes. Test the waters, see what triggers responses from your users.
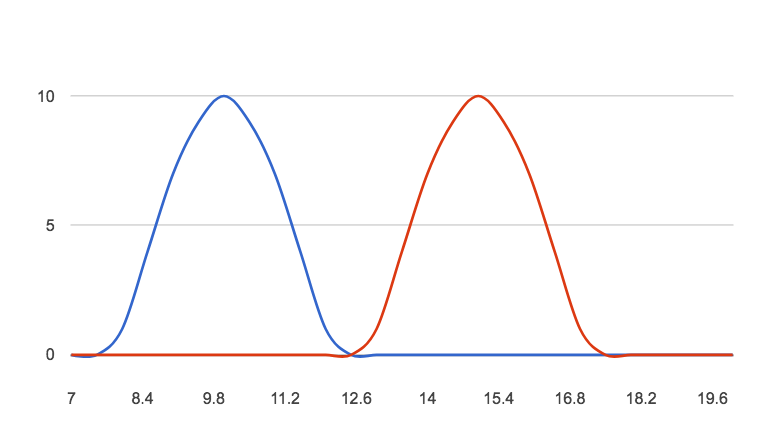
We mentioned A/B testing earlier in the article. Statistical significance plays an important role in this experiment, and it’s based on a cause-effect relationship. A good example of A/B testing is changing the color of a button within your app. (It can be the button in your in-app feedback survey!).
Which version drives better response rates from your users? Statistical significance can back you up and give you confidence that the changes you want to implement are positive ones, so that in lieu of enough feedback, you can still make smart moves to improve your app.
Monitoring the impacts of the changes you make is critical to ensure that you’re not doing damage to your app in the process.
The Next Steps
Feedback has an integral part in a successful software business. At Contextual, we can help your journey towards product adoption easier by focusing not only on capturing feedback, but also on onboarding, feature discovery, and much more. Book a demo with us today to learn more!Image Credit

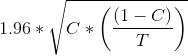 = 1.96 * SQRT(0.1 * (1-0.1) / 1000)= 0.00949
= 1.96 * SQRT(0.1 * (1-0.1) / 1000)= 0.00949